
Zoi Roupakia
Attention Without Understanding (2026)
A line drawing. No instruction. DINOv2, a self-supervised Vision Transformer, attended to it through twelve independent heads, each weighting the image differently, none aware of the others.
Like the inhabitants of Plato’s Cave, the model perceives only the shadows of geometry, forever separated from the “Form” by a veil of its own making.
Left: The Form
Centre: The Conflict
Right: The Gaze
Technical note: The centre panel visualises the standard deviation across twelve individual self-attention heads; the right panel visualises the mean attention across the same heads. These maps are derived from the final transformer block of DINOv2 ViT-B/14 via the [CLS] token, and projected into image space using bicubic interpolation and Gaussian smoothing.
A visual exploration of machine perception through self-attention maps extracted from DINOv2.
ARTIST STATEMENT
Attention Without Understanding explores a form of digital Platonic realism. The work frames a self-supervised Vision Transformer as a modern inhabitant of Plato’s Cave, perceiving only the mathematical “shadows” of geometry while remaining separated from the “Form” by a veil of its own making.
While the model can map the “shadows”, edges and spatial patterns, it lacks “noesis”, the capacity to access the semiotic structure through which humans read meaning in a single line. By stripping away labels and technical clutter, the triptych reveals the gap between human meaning-making and algorithmic perception, inviting the viewer to witness a machine attending to patterns it can weight mathematically but cannot truly understand.
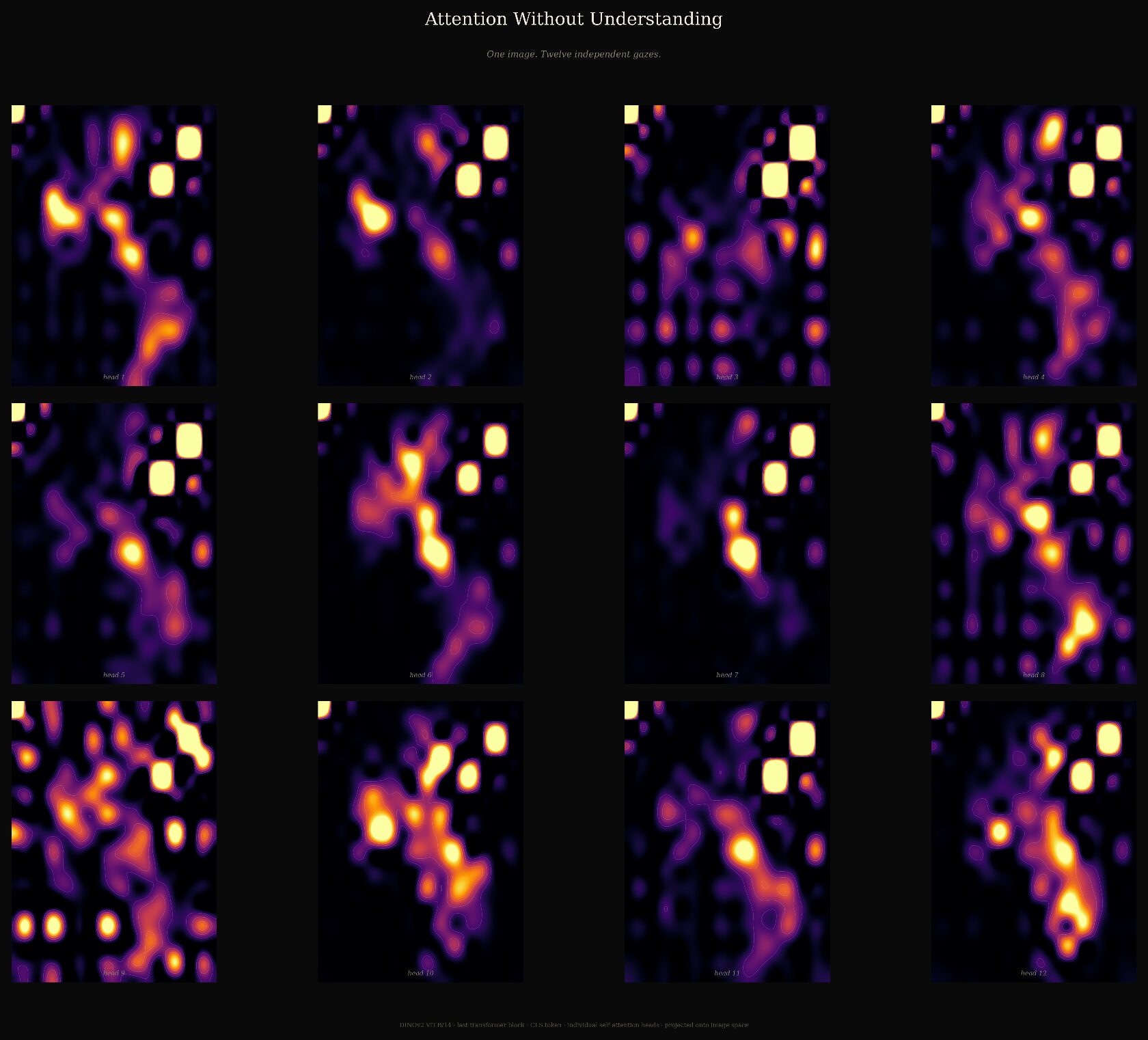
Output of twelve individual self-attention heads from the last transformer block of DINOv2.
TECHNICAL DEEP DIVE: THE TWELVE GAZES
One image. Twelve independent gazes.
This visualisation probes the internal logic of the DINOv2 (ViT-B/14) architecture. Unlike supervised models that are explicitly trained to recognise labelled objects, DINOv2 is self-supervised: it learns visual structure through self-distillation.
The grid above displays the individual attention heads from the final transformer block, extracted via the [CLS] token. The result reveals a fragmented machine perception. Some heads focus on local curvature, such as the lips and chin. Other heads attend to global spatial relationships or negative space. The variance between them exposes a model that can identify patterns while lacking semantic grounding.
The image below shows “The Alignment of Gaze”: an overlay of Head 10 on the original drawing, demonstrating the mathematical precision with which transformer attention isolates salient edges without semantic understanding.

The Alignment of Gaze.
CREDITS
Model: DINOv2 ViT-B/14
Audio: Adapted from CC0 recordings sourced via Freesound.org, including:
Neutral ambient drone by xkeril: https://freesound.org/s/609895/
Complex shifting ambient drone 8 by +frame+: https://freesound.org/s/845842/
Drone-e_tale_14.aif by _bil_: https://freesound.org/s/402887/
Quasi Drone – A Low Frequency Ambient Drone Soundscape by bassimat: https://freesound.org/s/840934/
All recordings licensed under Creative Commons 0 (CC0).

Zoi Roupakia is an AI scientist and founder of Noetic AI, working at the intersection of artificial intelligence, perception, and technology policy. She is also a Policy Affiliate at the University of Cambridge. With a background spanning machine learning research (Google patent co-inventor), industrial practice, and innovation policy, her artistic work explores how intelligent systems represent, abstract, and interpret the world through themes of cognition, symbolism, and algorithmic vision.